
Redesigning Etsy’s Machine Learning Platform


Introduction
Etsy leverages machine learning (ML) to create personalized experiences for our millions of buyers around the world with state-of-the-art search, ads, and recommendations. The ML Platform team at Etsy supports our machine learning experiments by developing and maintaining the technical infrastructure that Etsy’s ML practitioners rely on to prototype, train, and deploy ML models at scale. When we built Etsy’s first ML platform back in 2017, our data science team was growing, and a lack of mature, enterprise-scale solutions for managing the models they were building threatened to become a bottleneck for ML model delivery. We decided the best way forward was to build systems in-house that would present Etsy’s ML practitioners with a consistent, end-to-end interface for training, versioning, packaging, and deploying the models they were building in their preferred ML modeling libraries.
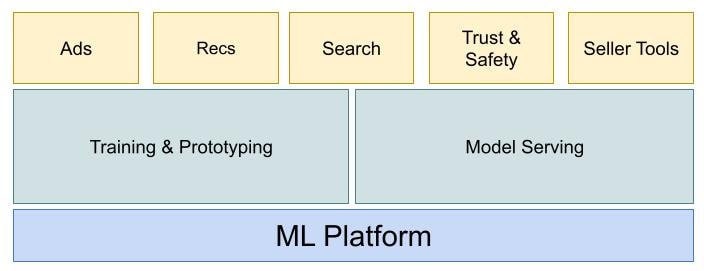
Our in-house solutions were written in 2017 when Etsy had a small data science team and we largely relied on a single implementation of logistic regression for production models. While our ML systems scaled well and were maintainable given Etsy’s size at the time, the maintenance cost started to grow with the increasing number and complexity of machine learning projects we had to support. In the industry, the number of third-party ML frameworks was exploding. It was becoming more difficult and costly to onboard new members of our data teams, who would have to drop tools they had already become proficient in to adapt themselves to our own V1 technology.
By 2020, it was time to cut the cord. We decided we could shed some of the technical debt our in-house systems had accrued by offloading platform responsibilities to the modern ML frameworks our customers were increasingly familiar with. We put together a working group with members from both the infrastructure and data science teams and asked them to draft a set of principles that would guide buildout of the second major version of Etsy’s end-to-end ML platform.
Above all in this iteration, we wanted to avoid building in-house tooling if possible. Our customers were already starting to experiment with open-source and managed technologies to work around the limitations of the V1 platform, and we wanted to collaborate with them. Leveraging managed solutions from Google Cloud and industry standard tooling such as TensorFlow would help new and existing ML practitioners train models quickly without having to rely on the platform team for help.
Moving our platform in the direction of self-service would allow it to scale to the rapidly increasing number of ML practitioners at Etsy. Instead of burdening our customers with platform-specific abstractions, we wanted to let well-built, well-documented open source tools speak for themselves. This would both unblock our customers, and free up the ML Platform team to focus away from support and more on its core work.
Given the internal momentum at Etsy behind TensorFlow, we decided to support that as our primary modeling framework. However, we didn’t want to limit customers to a single toolset as we had in V1. Anything we built would need to be flexible enough to allow ML practitioners to experiment and deploy models using any ML libraries.
With these principles we began to evaluate technologies suitable for replacing the solutions we had built in version 1 of our platform.
Etsy’s ML Platform V2
Training and Prototyping
ML experimentation is a highly iterative process, requiring many ad hoc experiments. Practitioners need to be able to train and prototype new models quickly, in whatever language or framework seems appropriate, and deploy them reliably. Given the amount of data Etsy works with, that means our infrastructure has to be robust and scalable.
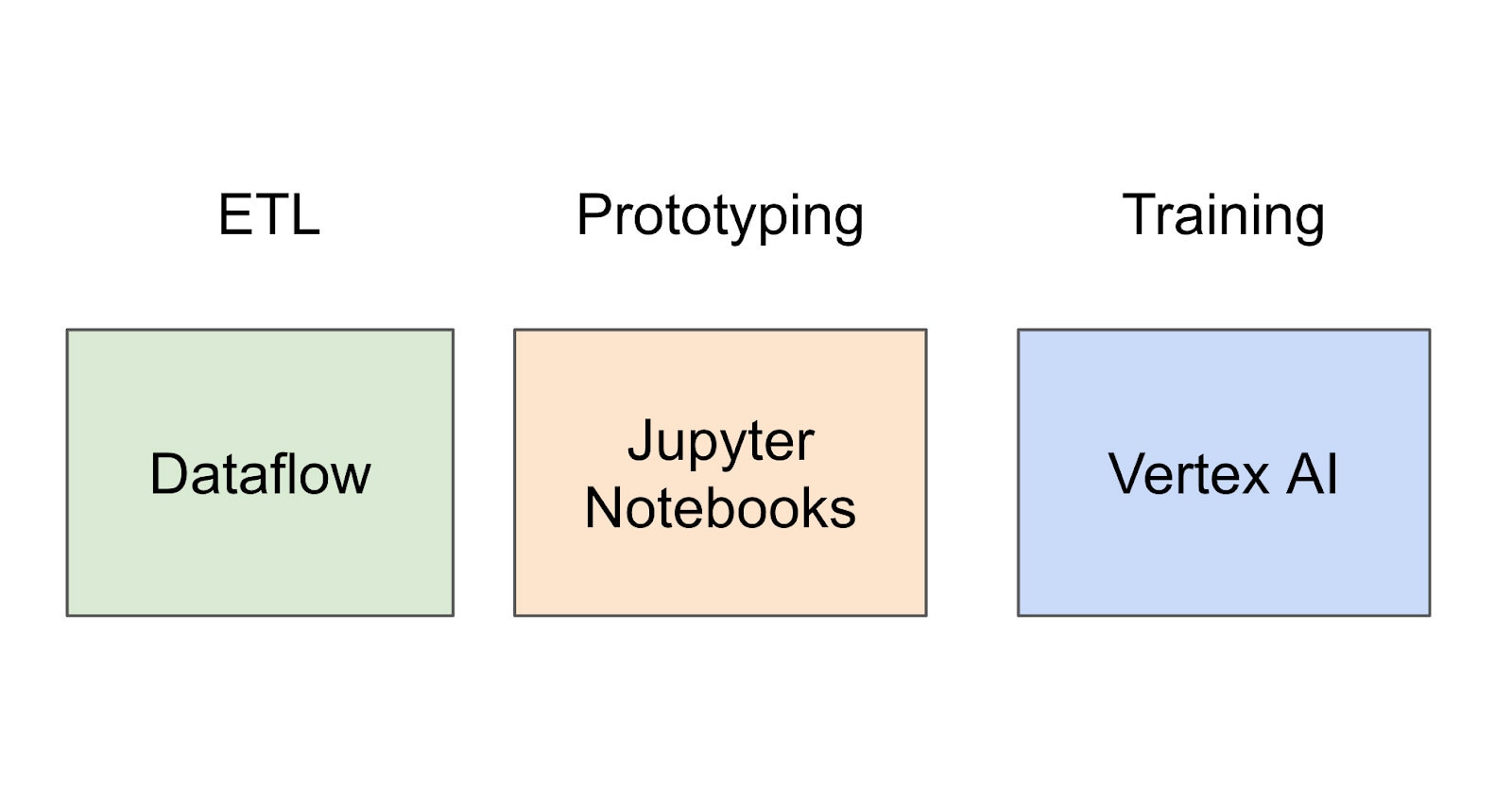
Our training and prototyping platform largely relies on Google Cloud services like Vertex AI and Dataflow, where customers can experiment freely with the ML framework of their choice. These services let customers easily leverage complex ML infrastructure (such as GPUs) through comfortable interfaces like Jupyter Notebooks. Massive extract transform load (ETL) jobs can be run through Dataflow while complex training jobs of any form can be submitted to Vertex AI for optimization.
While the ML Platform provides first-class support for TensorFlow as an ML modeling framework, customers can experiment with any model using ad hoc notebooks or managed training code and in-house Python distributions.
Model Serving
To deploy models for inference, customers typically create stateless ML microservices deployed in our Kubernetes cluster to serve requests from Etsy’s website or mobile app. We manage these deployments through an in-house control plane, the Model Management Service, which provides customers with a simple UI to manage their model deployments.
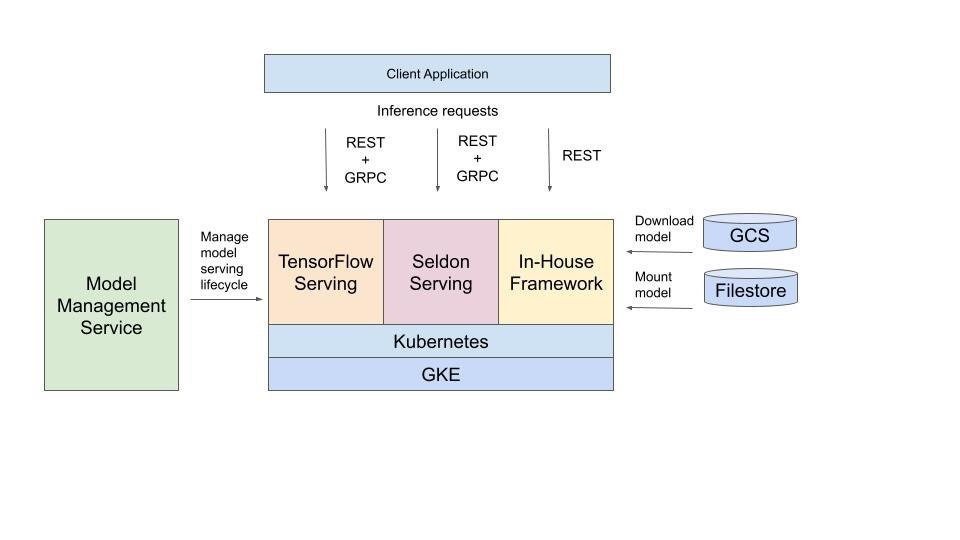
When we evaluated products to replace the Model Management Service, we realized that what we’d already built ourselves was still the best tool to meet our needs. So we decided to violate our architectural principle of not building in-house, extending the Model Management Service to support two additional open-source serving frameworks: TensorFlow Serving and Seldon Core. TensorFlow Serving provides a standard, repeatable way of deploying TensorFlow models in containers, while Seldon Core lets customers write custom ML inference code for other use cases. The ability to deploy both of these new solutions through the Model Management Service aligns with our principle of being flexible, but still TensorFlow first.
Workflow Orchestration
Maintaining up-to-date, user-facing models requires robust pipelines for retraining and deployment. While Airflow is Etsy’s primary choice for general workflow orchestration, Kubeflow provides many ML native features and was already being leveraged internally by the ML platform team. We also wanted to complement our first-class TensorFlow support by introducing TFX pipelines and other TensorFlow-native frameworks.
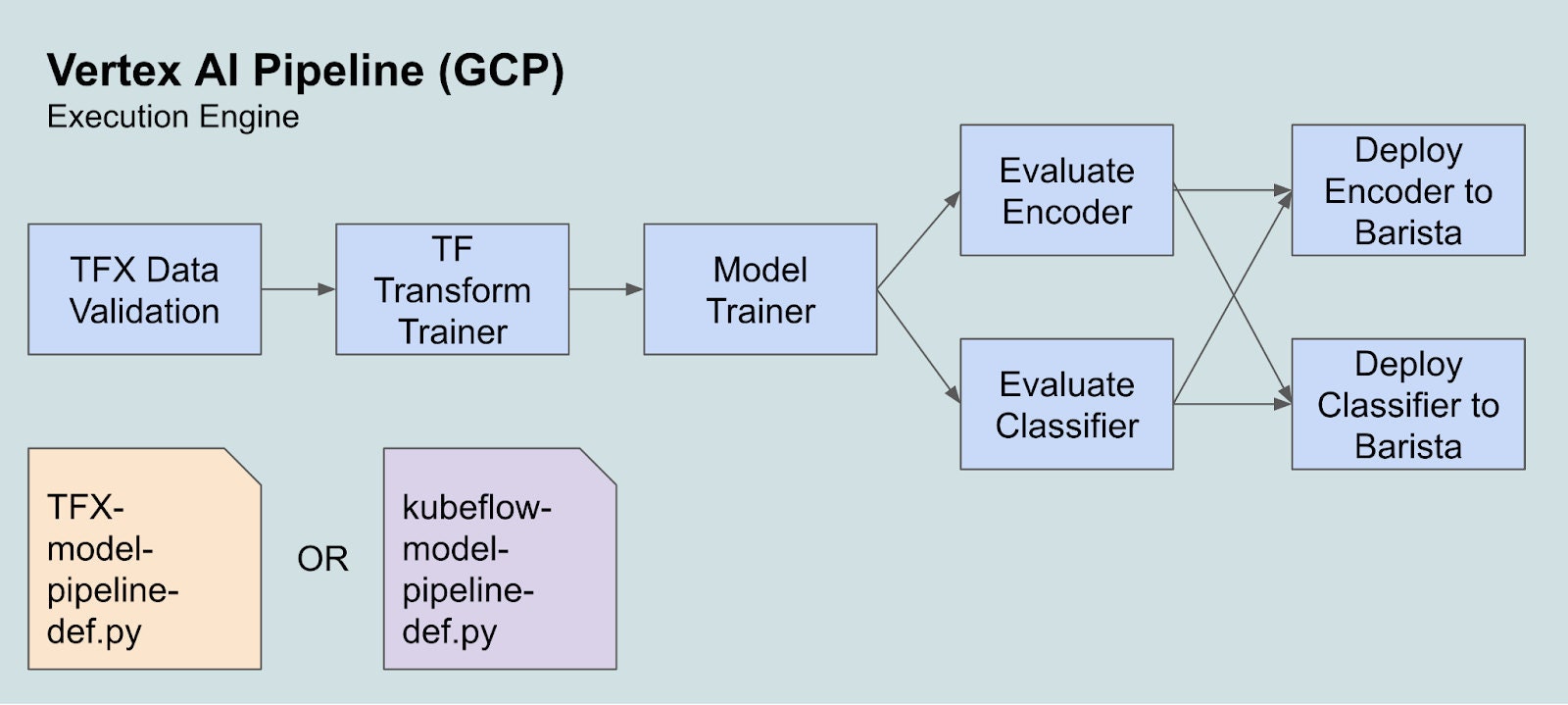
Moving to GCP’s Vertex AI Pipelines lets ML practitioners develop and test pipelines using either the Kubeflow or TFX SDK, based on their chosen model framework and preference. The time it takes for customers to write, test, and validate pipelines has dropped significantly. ML practitioners can now deploy containerized ML pipelines that easily integrate with other cloud ML services and can test directed acyclic graphs (DAGs) locally, further speeding up the development feedback loop.
Outcomes
Rollout of V2 has been incremental, with a focus on delivering the most valuable and user-centric new features upfront. In fact it’s a testament to the good design and extensibility of V1 that we’ve been able to do this while continuing to support and maintain all the original platform features.
ML platform V2 customers have already experienced dramatic boosts in productivity. We’re estimating a ~50% reduction in the time it takes to go from idea to live ML experiment. A single product team was able to complete over 2000 offline experiments in Q1 alone. Using services like Google’s Vertex AI, ML practitioners can now prototype new model architectures in days rather than weeks, and launch dozens of hyperparameter tuning experiments with a single command.
Challenges and Learnings
Adoption, perhaps surprisingly, has emerged as one of our biggest challenges. Migrating to a new platform always requires upfront effort that may not align with an ML practitioner’s current priorities. It’s understandable that the effort to replace a working Airflow DAG to a Kubeflow Pipeline might not seem high priority, even when customers are excited about the new tools in the abstract. We have been providing additional support to early adopters in order to ease the transition.
The enhanced flexibility of our new platform means ML practitioners can easily write most of their own code, but it has also led to performance issues with libraries like Tensorflow Transform (TFT) – a library for preprocessing input features that runs at inference time. Seemingly small inefficiencies such as non-vectorized code can result in a massive performance degradation, and in some cases we’ve seen that optimizing a single TFT function can reduce the model runtime from 200ms to 4ms. These issues can be difficult to troubleshoot, especially as our team has had to adapt from owning all the code in the platform to supporting third-party tools and services. To mitigate the problem, we’ve been putting forth some TensorFlow best practices and centralizing TFT code so that data can reuse and share well-tested, performant transformations.
When we began building out V2, we were guided by the notion of treating the platform as a product. The critical lesson we’ve learned is that you have to remember that mantra at every stage of the work. When you’re creating new platform components and new features, transparency is a key factor. There’s no guarantee that customers will come to you on their own with their concerns. You have to reach out to them throughout development to share goals, target dates, and resources if you want to drive adoption and usage of your new platform.
Future Work
Both the migration and development of ML Platform V2 are ongoing. Including experimental models, we currently have almost 90 ML Platform V1 model deployments in production – each with an Airflow DAG of its own that would have to be rewritten for V2 compatibility. While the basis for all training and serving components are in place, as always new use cases bring new problems and opportunities for development.
Beyond that, we continue to think broadly about next-generation ML platform capabilities. From automation and continuous delivery to ML governance components like statistical observability or model registries, we are again gathering user requirements and preparing to build on the next iteration of our ever-evolving platform.
Special thanks to Rob Miles for co-authoring, Sallie Walecka for creating the images, the fantastic Code as Craft team for their review and support, and lastly all current and past members of the ML platform team at Etsy!


